Keras Tips - Tensorflow 2.0
Tensorflow, Keras를 이용하여 딥러닝에 필요한 스킬들을 기본적인 샘플을 만들어 보았다.
Neural Network Frameworks - Tensorflow 2.0
학습목표
- Part 1: 모델 아키텍쳐를 어떻게 선택하는 지 배우게 됩니다.
- Part 2: 정규화(Regularization) 전략을 배웁니다.
- Part 3: 다양한 활성함수를 사용함에 발생하는 trade-off 애 대해서 논의배볼 수 있어야 합니다.
Lets Use Libraries !
지난 이틀간의 목표는 신경망의 배경, 기초, 용어, 네트워크 구조, 전파/역전파, 오류/비용 함수, 에폭(Epoch), 그리고 경사하강법 등을 숙지하는 것이었죠. Perceptrons(단일 노드 신경망)와 Feed-Forward Neural Networks라고도 알려진 Multi-Layer Perceptrons를 포함하여 간단한 신경망을 손으로 코딩하도록 요구하여 함으로써 신경망에 익숙해지기 위해 노력해왔죠. 수작업으로 일을 계속하는 것은 우리의 한정된 시간을 사용하는 최선의 방법은 아닐 것이라는 것을 그간의 과정을 통해서 알고 있습니다. 이제는 손으로 하는 일을 졸업할 준비가 되어 있으시죠? 실무에서 적용 가능한 예측 모델을 만들기 위해 강력한 라이브러리를 사용하기 시작할 것입니다. 기대해주세요.
Overview
딥러닝 연구자들의 일부는 신경망을 위한 아키텍쳐(구조)을 선택하는 것은 과학이라기 보다는 예술에 가깝다고 말합니다.
용도에 맞는 구조를 선택하는 가장 좋은 방법은 연구와 실험을 통해서 발견할 수 있기 때문입니다.
# 파일 선택을 통해 예제 데이터를 내 컴퓨터에서 불러옵니다.
# 강의 목적상 내 데이터를 대신하여 서버에서 불러오도록 하겠습니다. 직접 가지고 있는 데이터를 사용하기 위해서는 주석처리된 files.upload()를 이용하시면 됩니다.
from google.colab import files
#uploaded = files.upload()
my_data = "https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/everydeep/ThoraricSurgery.csv"
# 딥러닝을 구동하는 데 필요한 케라스 함수를 불러옵니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import tensorflow.keras.layers as Layer
import tensorflow as tf
# 케라스 외의 필요한 라이브러리를 불러옵니다.
import numpy as np
import tensorflow as tf
# 실행할 때마다 같은 결과를 출력하기 랜덤함수를 고정하는 부분입니다.
# 랜덤함수의 Seed를 고정하게 되면 랜덤함수가 항상 일정하게 나옵니다.
np.random.seed(3)
tf.random.set_seed(3)
# 불러온 데이터를 적용합니다.
# pandas외에도 읽을 수 있는 방법이 있습니다. 편하신 방법을 사용하시면 됩니다.
Data_set = np.loadtxt(my_data, delimiter=",")
# 환자의 기록과 수술 결과를 X와 Y로 구분하여 저장합니다.
X = Data_set[:,0:17]
Y = Data_set[:,17]
# 딥러닝 구조를 결정합니다(모델을 설정하고 실행하는 부분입니다).
model = Sequential([
Dense(30, input_dim=17, activation='relu'),
Layer.Dropout(0.5),
Dense(30, input_dim=17, activation='relu'),
Dense(1, activation='sigmoid') # 분류할 방법에 따라 개수를 조정해야 합니다.
])
# 딥러닝을 실행합니다.
model.compile(loss='mean_squared_logarithmic_error', optimizer='adam', metrics=['accuracy']) # mean_squared_error # binary_crossentropy # mean_absolute_error # poisson
history = model.fit(X, Y, epochs=30, batch_size=30)
오차함수
평균제곱계열
- mean_squared_error
- mean_absolute_error
- mean_absolute_percentage_error
- mean_squared_logarithmic_error
엔트로피계열
- binary_crossentropy
- categorical_crossentropy
Regularization Strategies (Learn)
Fashion MNIST를 불러와서 더 많은 라이브러리의 도구들을 활용해보겠습니다.
Deep Learning Training Tricks
Neural Networks는 매개변수가 아주 많은 모델이어서, Section 2에서 공부했던 것처럼 훈련 데이터에 쉽게 과대적합(overfit) 오버핏될 수 있다. 이 문제를 해결하는 가장 중요한 방법은 정규화 전략이다.

우리가 간단히 다루는 신경망에는 네 가지 일반적인 정규화 방법이 있다. 이러한 구성 요소를 적용하는 방법:
- 항상 EarlyStopping을 사용한다. 이 전략은 당신의 가중치의 최고 유용성 시점을 훨씬 지나서 더 업데이트되는 것을 막을 것이다.
- EarlyStopping, 가중치 감소(Weight Decay) 및 Dropout 사용
- EarlyStopping, 가중치 제약(Constraint) 및 Dropout 사용
Weight Decusion and Weight Restriction은 유사한 목적을 달성하여 값을 정규화하여 매개변수를 과도하게 적합시키는 것을 방지한다. 그 역학들은 약간 다를 뿐이다. 그렇기 때문에 굳이 같이 적용하지 않아도 될 것이다.
from tensorflow.keras.datasets import fashion_mnist
# 데이터 불러오기
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
print(X_train.shape, X_test.shape)
# 데이터를 정규화 합니다
X_train = X_train / 255.
X_test = X_test /255.
# 클래스를 확인합니다.
np.unique(y_train)
(60000, 28, 28) (10000, 28, 28)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
import keras, os
# 모델 구성을 확인합니다.
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(10, activation='softmax')
])
# 업데이트 방식을 설정합니다.
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
# 총 7850 parameters (10 bias)
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 7850
=================================================================
Total params: 7,850
Trainable params: 7,850
Non-trainable params: 0
_________________________________________________________________
# 모델 학습
# 변수 설정을 따로 하는 방법을 적용하기 위한 코드입니다.
batch_size = 30
epochs_max = 30
# 학습시킨 데이터를 저장시키기 위한 코드입니다.
checkpoint_filepath = "tmp/FMbest.hdf5"
# overfitting을 방지하기 위해서 학습 중 early stop을 수행하기 위한 코드입니다.
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
# Validation Set을 기준으로 가장 최적의 모델을 찾기 위한 코드입니다.
save_best = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath, monitor='val_loss', verbose=1, save_best_only=True,
save_weights_only=True, mode='auto', save_freq='epoch', options=None)
# 모델 학습 코드 + early stop + Best model
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs_max, verbose=1,
validation_data=(X_test,y_test),
callbacks=[early_stop, save_best])
Epoch 1/30
1993/2000 [============================>.] - ETA: 0s - loss: 0.4313 - accuracy: 0.8517
Epoch 00001: val_loss improved from inf to 0.46641, saving model to tmp/FMbest.hdf5
2000/2000 [==============================] - 3s 1ms/step - loss: 0.4312 - accuracy: 0.8517 - val_loss: 0.4664 - val_accuracy: 0.8410
Epoch 2/30
1966/2000 [============================>.] - ETA: 0s - loss: 0.4206 - accuracy: 0.8549
Epoch 00002: val_loss did not improve from 0.46641
2000/2000 [==============================] - 2s 1ms/step - loss: 0.4208 - accuracy: 0.8548 - val_loss: 0.4769 - val_accuracy: 0.8285
Epoch 3/30
1961/2000 [============================>.] - ETA: 0s - loss: 0.4114 - accuracy: 0.8574
Epoch 00003: val_loss improved from 0.46641 to 0.45834, saving model to tmp/FMbest.hdf5
2000/2000 [==============================] - 2s 1ms/step - loss: 0.4114 - accuracy: 0.8573 - val_loss: 0.4583 - val_accuracy: 0.8367
Epoch 4/30
1980/2000 [============================>.] - ETA: 0s - loss: 0.4060 - accuracy: 0.8596
Epoch 00004: val_loss improved from 0.45834 to 0.45518, saving model to tmp/FMbest.hdf5
2000/2000 [==============================] - 2s 1ms/step - loss: 0.4057 - accuracy: 0.8595 - val_loss: 0.4552 - val_accuracy: 0.8394
Epoch 5/30
1967/2000 [============================>.] - ETA: 0s - loss: 0.4002 - accuracy: 0.8616
Epoch 00005: val_loss improved from 0.45518 to 0.44881, saving model to tmp/FMbest.hdf5
2000/2000 [==============================] - 2s 1ms/step - loss: 0.4002 - accuracy: 0.8616 - val_loss: 0.4488 - val_accuracy: 0.8442
Epoch 6/30
1969/2000 [============================>.] - ETA: 0s - loss: 0.3972 - accuracy: 0.8619
Epoch 00006: val_loss improved from 0.44881 to 0.44599, saving model to tmp/FMbest.hdf5
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3969 - accuracy: 0.8620 - val_loss: 0.4460 - val_accuracy: 0.8441
Epoch 7/30
1990/2000 [============================>.] - ETA: 0s - loss: 0.3943 - accuracy: 0.8634
Epoch 00007: val_loss did not improve from 0.44599
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3944 - accuracy: 0.8633 - val_loss: 0.4483 - val_accuracy: 0.8453
Epoch 8/30
1966/2000 [============================>.] - ETA: 0s - loss: 0.3916 - accuracy: 0.8642
Epoch 00008: val_loss improved from 0.44599 to 0.43865, saving model to tmp/FMbest.hdf5
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3918 - accuracy: 0.8642 - val_loss: 0.4386 - val_accuracy: 0.8448
Epoch 9/30
1983/2000 [============================>.] - ETA: 0s - loss: 0.3890 - accuracy: 0.8654
Epoch 00009: val_loss did not improve from 0.43865
2000/2000 [==============================] - 3s 1ms/step - loss: 0.3896 - accuracy: 0.8652 - val_loss: 0.4488 - val_accuracy: 0.8424
Epoch 10/30
2000/2000 [==============================] - ETA: 0s - loss: 0.3871 - accuracy: 0.8648
Epoch 00010: val_loss did not improve from 0.43865
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3871 - accuracy: 0.8648 - val_loss: 0.4514 - val_accuracy: 0.8388
Epoch 11/30
1968/2000 [============================>.] - ETA: 0s - loss: 0.3851 - accuracy: 0.8661
Epoch 00011: val_loss did not improve from 0.43865
2000/2000 [==============================] - 3s 1ms/step - loss: 0.3855 - accuracy: 0.8659 - val_loss: 0.4461 - val_accuracy: 0.8441
Epoch 12/30
1968/2000 [============================>.] - ETA: 0s - loss: 0.3828 - accuracy: 0.8659
Epoch 00012: val_loss did not improve from 0.43865
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3838 - accuracy: 0.8658 - val_loss: 0.4496 - val_accuracy: 0.8436
Epoch 13/30
1992/2000 [============================>.] - ETA: 0s - loss: 0.3823 - accuracy: 0.8659
Epoch 00013: val_loss did not improve from 0.43865
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3824 - accuracy: 0.8659 - val_loss: 0.4418 - val_accuracy: 0.8455
Epoch 14/30
1959/2000 [============================>.] - ETA: 0s - loss: 0.3819 - accuracy: 0.8666
Epoch 00014: val_loss did not improve from 0.43865
2000/2000 [==============================] - 3s 1ms/step - loss: 0.3815 - accuracy: 0.8667 - val_loss: 0.4461 - val_accuracy: 0.8451
Epoch 15/30
1983/2000 [============================>.] - ETA: 0s - loss: 0.3799 - accuracy: 0.8664
Epoch 00015: val_loss did not improve from 0.43865
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3796 - accuracy: 0.8665 - val_loss: 0.4760 - val_accuracy: 0.8332
Epoch 16/30
1964/2000 [============================>.] - ETA: 0s - loss: 0.3787 - accuracy: 0.8679
Epoch 00016: val_loss did not improve from 0.43865
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3793 - accuracy: 0.8675 - val_loss: 0.4632 - val_accuracy: 0.8354
Epoch 17/30
1986/2000 [============================>.] - ETA: 0s - loss: 0.3786 - accuracy: 0.8673
Epoch 00017: val_loss did not improve from 0.43865
2000/2000 [==============================] - 3s 1ms/step - loss: 0.3782 - accuracy: 0.8673 - val_loss: 0.4503 - val_accuracy: 0.8399
Epoch 18/30
1967/2000 [============================>.] - ETA: 0s - loss: 0.3762 - accuracy: 0.8683
Epoch 00018: val_loss did not improve from 0.43865
2000/2000 [==============================] - 3s 1ms/step - loss: 0.3761 - accuracy: 0.8683 - val_loss: 0.4647 - val_accuracy: 0.8369
Epoch 00018: early stopping
<tensorflow.python.keras.callbacks.History at 0x7fa47c7885c0>
# last model
model.predict(X_test[0:1])
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
model.load_weights(checkpoint_filepath)
# best model # 테스트 데이터 예측 정확도
model.predict(X_test[0:1])
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
Weight Decay
Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01)))
# 모델 구성을 확인합니다.
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01)),
Dense(10, activation='softmax')
])
# 업데이트 방식을 설정합니다.
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_6 (Flatten) (None, 784) 0
_________________________________________________________________
dense_12 (Dense) (None, 64) 50240
_________________________________________________________________
dense_13 (Dense) (None, 10) 650
=================================================================
Total params: 50,890
Trainable params: 50,890
Non-trainable params: 0
_________________________________________________________________
2000/2000 [==============================] - 4s 2ms/step - loss: 1.0228 - accuracy: 0.7967 - val_loss: 0.7873 - val_accuracy: 0.8117
<tensorflow.python.keras.callbacks.History at 0x7fa472aa6a90>
constraints
from tensorflow.keras.constraints import MaxNorm
from tensorflow.keras import regularizers
# 모델 구성을 확인합니다.
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01),
kernel_constraint=MaxNorm(2.)), ## add constraints
Dense(10, activation='softmax')
])
# 업데이트 방식을 설정합니다.
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_7 (Flatten) (None, 784) 0
_________________________________________________________________
dense_14 (Dense) (None, 64) 50240
_________________________________________________________________
dense_15 (Dense) (None, 10) 650
=================================================================
Total params: 50,890
Trainable params: 50,890
Non-trainable params: 0
_________________________________________________________________
2000/2000 [==============================] - 4s 2ms/step - loss: 1.0300 - accuracy: 0.7935 - val_loss: 0.8100 - val_accuracy: 0.7969
<tensorflow.python.keras.callbacks.History at 0x7fa47218cc50>
Dropout
from tensorflow.keras.layers import Dropout
from tensorflow.keras.constraints import MaxNorm
from tensorflow.keras import regularizers
# 모델 구성을 확인합니다.
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01),
kernel_constraint=MaxNorm(2.)),
Dropout(0.5) , ## add dropout
Dense(10, activation='softmax')
])
# 업데이트 방식을 설정합니다.
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))
Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_8 (Flatten) (None, 784) 0
_________________________________________________________________
dense_16 (Dense) (None, 64) 50240
_________________________________________________________________
dropout_2 (Dropout) (None, 64) 0
_________________________________________________________________
dense_17 (Dense) (None, 10) 650
=================================================================
Total params: 50,890
Trainable params: 50,890
Non-trainable params: 0
_________________________________________________________________
2000/2000 [==============================] - 4s 2ms/step - loss: 1.2095 - accuracy: 0.7678 - val_loss: 0.9194 - val_accuracy: 0.7994
<tensorflow.python.keras.callbacks.History at 0x7fa47184d668>
Learning rate decay
tf.keras.optimizers.Adam(
learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False,
name='Adam'
)
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001, beta_1 = 0.89)
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))
Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_8 (Flatten) (None, 784) 0
_________________________________________________________________
dense_16 (Dense) (None, 64) 50240
_________________________________________________________________
dropout_2 (Dropout) (None, 64) 0
_________________________________________________________________
dense_17 (Dense) (None, 10) 650
=================================================================
Total params: 50,890
Trainable params: 50,890
Non-trainable params: 0
_________________________________________________________________
2000/2000 [==============================] - 4s 2ms/step - loss: 0.9239 - accuracy: 0.7904 - val_loss: 0.8825 - val_accuracy: 0.8008
<tensorflow.python.keras.callbacks.History at 0x7fa470ebc668>
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=1e-2,
decay_steps=10000,
decay_rate=0.9)
optimizer = keras.optimizers.SGD(learning_rate=lr_schedule)
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=1e-2,
decay_steps=10000,
decay_rate=0.9)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=lr_schedule)
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))
Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_8 (Flatten) (None, 784) 0
_________________________________________________________________
dense_16 (Dense) (None, 64) 50240
_________________________________________________________________
dropout_2 (Dropout) (None, 64) 0
_________________________________________________________________
dense_17 (Dense) (None, 10) 650
=================================================================
Total params: 50,890
Trainable params: 50,890
Non-trainable params: 0
_________________________________________________________________
2000/2000 [==============================] - 4s 2ms/step - loss: 1.9766 - accuracy: 0.6658 - val_loss: 1.6802 - val_accuracy: 0.7042
<tensorflow.python.keras.callbacks.History at 0x7fa47183def0>
def decayed_learning_rate(step):
step = min(step, decay_steps)
cosine_decay = 0.5 * (1 + cos(pi * step / decay_steps))
decayed = (1 - alpha) * cosine_decay + alpha
return initial_learning_rate * decayed
first_decay_steps = 1000
initial_learning_rate = 0.01
lr_decayed_fn = (
tf.keras.experimental.CosineDecayRestarts(
initial_learning_rate,
first_decay_steps))
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=lr_schedule)
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))
Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_8 (Flatten) (None, 784) 0
_________________________________________________________________
dense_16 (Dense) (None, 64) 50240
_________________________________________________________________
dropout_2 (Dropout) (None, 64) 0
_________________________________________________________________
dense_17 (Dense) (None, 10) 650
=================================================================
Total params: 50,890
Trainable params: 50,890
Non-trainable params: 0
_________________________________________________________________
2000/2000 [==============================] - 5s 2ms/step - loss: 1.9408 - accuracy: 0.6564 - val_loss: 1.6923 - val_accuracy: 0.7560
<tensorflow.python.keras.callbacks.History at 0x7fa473a39e80>
Activation Functions (추가학습)
Tanh Function
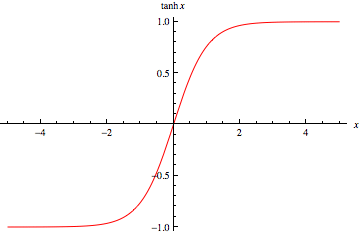
만약 sigmoid 함수가 0에서 멀어질 때 바로 그렇게 평평해지지 않고 중간에 조금 더 뾰족해진다면? 그것은 기본적으로 Tanh 기능이다. Tanh 함수는 실제로 y 치수에서 sigmoid 함수를 2로 스케일링하고 모든 값에서 1을 빼면 생성될 수 있다. 기본적으로 sigmoid와 동일한 성질을 가지며, 여전히 우리가 0에서 멀어질수록 평평한 구배 감소에 어려움을 겪고 있지만, 그 파생상품은 0 주위에 더 높아져 가중치가 극단으로 조금 더 빠르게 이동한다.
Leaky ReLU
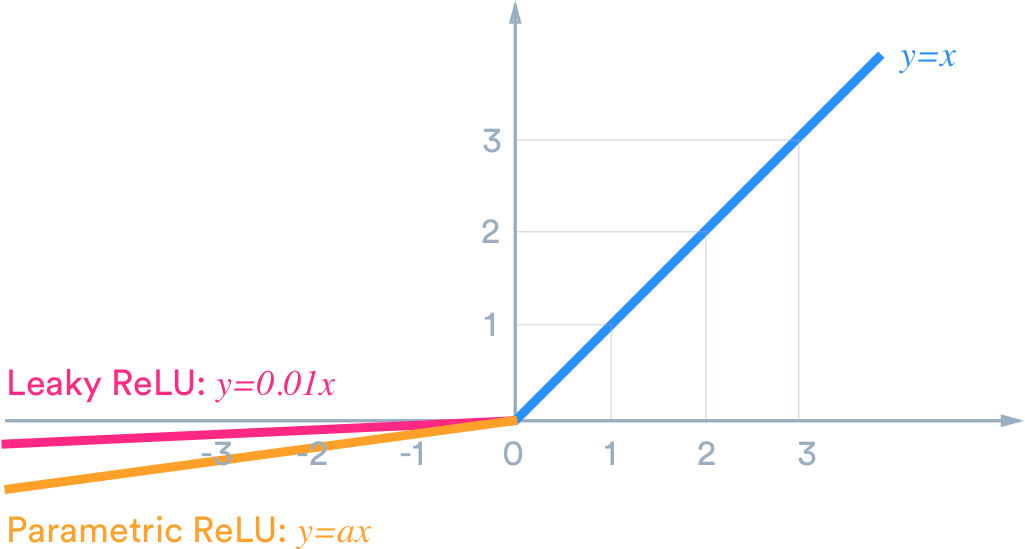
ReLU가 제일 좋다고만 들었는데, 인성에 문제가 있어? 보통 그래프의 왼쪽 절반(음수)의 함수는 뉴런이 활성화되지 않도록 하는 것을 알고 있죠. 가중치로 초기화된 뉴런의 경우, 우리의 구배는 뉴런의 가중치를 업데이트하지 않을 것이며, 이것은 결코 발화하지 않고 가중치이 업데이트하지 않는 죽은 뉴런, 쓸데없이 메모리를 차지하는 뉴런으로 될 수 있음을 보여준다. 우리는 아마도 초기 가중치가 안 좋게 생성되는 경우를 대비해서 조금이라도 발화하지 않는 뉴런의 가중치를 업데이트하고 미래에 다시 켤 수 있는 기회를 주고 싶을 것이다.
Leaky ReLU는 정확히 그것을 해결합니다! 파생 기능 왼쪽(음수)에서 0의 경사를 피함으로 해결합니다. 이는 ‘죽은' 뉴런도 충분한 반복에 의해 재생될 가능성이 있다는 것을 의미한다. 일부 규격에서는 누출되는 좌측의 기울기를 모델의 하이퍼 파라미터로 실험할 수도 있다!
Softmax Function

sigmoid 함수와 유사하지만 다중 클래스 분류 문제에 더 유용하다. 소프트맥스 함수는 모든 입력 집합을 취하여 최대 1까지 합한 확률로 변환할 수 있다. 이것은 우리가 어떤 출력물 목록을 던질 수 있다는 것을 의미하며, 그것은 확률로 변환할 것이고, 이것은 다중 클래스 분류 문제에 매우 유용하다. 예를 들어 MNIST처럼…